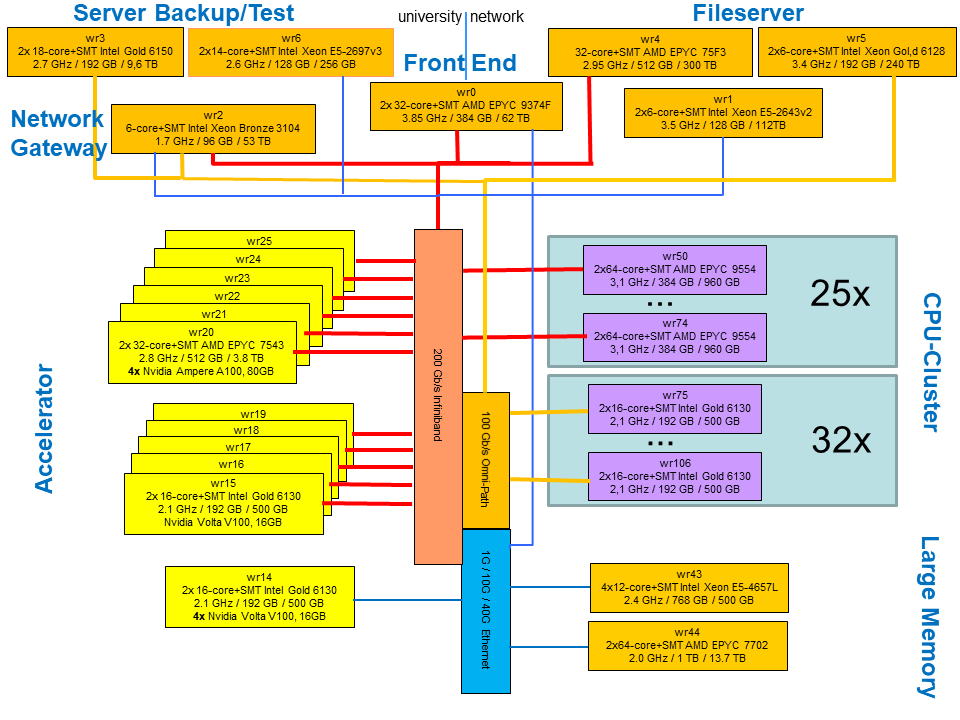
one front-end node wr0 for interactive access and administration as well as several server
a sub-cluster WR-I with 25 nodes wr50-wr74 with 2 64-core 2-way hyperthreaded AMD EPYC 9554 (a total of 6,400 way parallelism), connected with 200 Gb/s Infiniband
a sub-cluster WR-II with 32 nodes wr75-wr106 with 2 16-core 2-way hyperthreaded Intel Xeon Gold 6130 (a total of 2,048 way parallelism), connected with 100 Gb/s Omni-Path
L3 cache: 24.75 MB, 11-way set associative, exclusive cache
6 memory channels per processor, theor. memory bandwidth 115.2 GB/s per processor
peak performance is 86.4 GigaFlops / processor core thread
Test System (wr6)
This older server acts as an internal test system.
Barebone Supermicro SYS-2028GR-TR with X10DRG-H mainboard
2 Intel Xeon E5-2697 v3 at 2.6 GHz with in total 56 hardware threads
4 memory channels per processor
128 GB DDR4-2133 memory
CPU Nodes
The CPU cluster part consists of two parts, one part with 25 systems wr50-wr74 based on newer AMD processors and a second part with 32 systems wr75-wr106 based on older Intel processors.
AMD-based CPU nodes
The cluster nodes wr50-wr74 are based on the Gigabyte barebone R183-Z90 rev.AAD1 with a MZ93-FS0 mainboard.
The specification for each cluster node is:
AMD EPYC 9554 (Genoa) at 3.1 GHz, each with in total 128 cores / hardware threads (we disabled hyperthreading on these nodes)
384 GB DDR5-4800 memory
960 GB SSD
200 Gb/s Infiniband
Some technical details for the processor:
L1 data cache: 32 KB, 8-way set associative, write-back, 64 bytes/line
The cluster nodes wr75-wr106 are based on the PowerEdge C6420 barebone from Dell, 4 grouped in a PowerEdge C6400 chassis.
The specification for each cluster node is:
Intel Xeon Gold 6130 and Intel Xeon Gold 6130-F at 2.1 GHz, each with in total 64 hardware threads
192 GB DDR4-2466 memory
480 GB SSD
100 Gb/s Intel Omni-Path through a Xeon Gold 6130-F
Some technical details for the processor:
L1 data cache: 32 KB, 8-way set associative, write-back, 64 bytes/line
6 memory channels per processor, theor. memory bandwidth 127.8 GB/s per processor
peak performance is 54.4 GigaFlops / processor core thread
Shared Memory Parallel Systems
Big Memory / Shared Memory Parallelism (wr44)
For shared memory jobs with a demand for large main memory, highly parallelism and/or high local IO demands there is this many-core shared memory server available based on the barebone Gigabyte R182-Z92 (rev 100) with a MZ92-FS0-00 mainboard.
2x AMD EPYC 7702 (Zen 2 / Rome) processors at 2 GHz (TurboBoost up to 3.35)
1 TB DDR4-2933 memory
4x Micron 9300 MAX-3DWPD (U.2, 3.2 TB) and 1x Samsung 970 EVO (M.2, 500 GB)
10 Gb/s Ethernet Intel Server Adapter X520-SR2
Some technical details for each processor:
64 cores, 2-way hyperthreading
L1 data cache per core: 32 KB, 8-way set associative, write-back, 64 bytes/line
L2 unified cache per core: 512 KB, 8-way set associative, write-back, 64 bytes/line
L3 unified victim cache shared by all cores: 256 MB, 16-way set associative, 64 bytes/line
8 memory channels
theor. memory bandwidth 187.71 GB/s per processor (with our DDR4-2933)
Big Memory / Shared Memory Parallelism (wr43)
For shared memory jobs with a demand for large main memory and/or highly parallelism there is this many-core shared memory server available based on the barebone Supermicro 8027T-TRF+.
4-way motherboard Supermicro X9QR7-TF+
4 Intel Xeon E5-4657L processors at 2.4 GHz (TurboBoost up to 2.9)
768 GB DDR3-1866 memory
500 GB Micron MX200 SSD
10 Gb/s Ethernet Intel Server Adapter X520-SR1
Some technical details for the processors:
12 cores, 2-way hyperthreading
L1 data cache per core: 32 KB, 8-way set associative, write-back, 64 bytes/line
L2 unified cache per core: 256 KB, 8-way set associative, write-back, 64 bytes/line
L3 unified cache shared by all cores: 30 MB, 128-way set associative, write-back, 64 bytes/line
4 memory channels
theor. memory bandwidth 59.7 GB/s per processor
Accelerator
GPU Computing (wr20-wr25)
These 6 nodes each have 4 Nvidia A100 SXM4 connected with NVLink.
Barebone Supermicro A+ Server 2124GQ-NART
mainboard H12DSG-Q-CPU6
2 AMD EPYC 7543 (Zen 3) at 2.8 GHz with in total 128 hardware threads
512 GiB DDR4-3200 memory
3.8 + 0.9 GB SSD
4 Nvidia HGX-A100 SXM4 with 80 GB memory connected by 600 GB/s NVLink
2 port 200 Gb/s Mellanox Infiniband adapter
Some technical details for the processor:
32 cores / 64 hardware threads
L1 data cache: 1 MiB, 8-way set associative, write-back, 64 bytes/line
There are several hardware restrictions using this cards (in total 4 devices):
Device 0: "NVIDIA A100-SXM4-80GB"
CUDA Driver Version / Runtime Version 11.6 / 11.6
CUDA Capability Major/Minor version number: 8.0
Total amount of global memory: 81070 MBytes (85007794176 bytes)
(108) Multiprocessors, (064) CUDA Cores/MP: 6912 CUDA Cores
GPU Max Clock rate: 1410 MHz (1.41 GHz)
Memory Clock rate: 1593 Mhz
Memory Bus Width: 5120-bit
L2 Cache Size: 41943040 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total shared memory per multiprocessor: 167936 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 5 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Enabled
Device supports Unified Addressing (UVA): Yes
Device supports Managed Memory: Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 193 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
GPU Computing (wr14)
This node has 4 Nvidia Tesla V100 SXM2 connected with NVLink.
Barebone Dell PowerEdge C4140
2 Intel Xeon Gold 6130 at 2.1 GHz with in total 64 hardware threads
6 memory channels per processor
192 GB DDR4-2466 memory
480 GB SSD
4 Nvidia Tesla V100 SXM2 with 16 GB memory connected by NVLink
Nvidia Tesla V100 SXM2 GPU (Volta architecture) with 5120 Cuda cores and 640 Tensor cores
15.7 TFlops / 7.8 TFlops / 125 TFlops peak performance 32 / 64 bit / tensor floating point performance
16 GB HBM2 memory
900 GB/s bandwidth to onboard memory
system interface PCIe 3.0 x16
300 GB/s NVLink interconnect bandwidth
The GPU implements the Nvidia Volta architecture
There are several hardware restrictions using this cards (in total 4 devices):
Device 0: "Tesla V100-SXM2-16GB"
CUDA Driver Version / Runtime Version 9.2 / 9.2
CUDA Capability Major/Minor version number: 7.0
Total amount of global memory: 16160 MBytes (16945512448 bytes)
(80) Multiprocessors, ( 64) CUDA Cores/MP: 5120 CUDA Cores
GPU Max Clock rate: 1530 MHz (1.53 GHz)
Memory Clock rate: 877 Mhz
Memory Bus Width: 4096-bit
L2 Cache Size: 6291456 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 5 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Enabled
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 26 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
GPU Computing (wr15-wr19)
These nodes have a Nvidia Tesla V100 PCIe.
Barebone Dell PowerEdge R740
2 Intel Xeon Gold 6130 at 2.1 GHz with in total 64 hardware threads
Nvidia Tesla V100 PCIe GPU (Volta architecture) with 5120 Cuda cores and 640 Tensor cores
14 TFlops / 7 TFlops / 112 TFlops peak performance 32 / 64 bit / tensor floating point performance
16 GB HBM2 memory
900 GB/s bandwidth to onboard memory
system interface PCIe 3.0 x16
The GPU implements the Nvidia Volta architecture
There are several hardware restrictions using this card:
Device 0: "Tesla V100-PCIE-16GB"
CUDA Driver Version / Runtime Version 9.2 / 9.2
CUDA Capability Major/Minor version number: 7.0
Total amount of global memory: 16160 MBytes (16945512448 bytes)
(80) Multiprocessors, ( 64) CUDA Cores/MP: 5120 CUDA Cores
GPU Max Clock rate: 1380 MHz (1.38 GHz)
Memory Clock rate: 877 Mhz
Memory Bus Width: 4096-bit
L2 Cache Size: 6291456 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 7 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Enabled
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 59 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
Networks
There are three networks where all nodes are connected to at least 2:
a service network
a fast interconnection network for communication in parallel applications (200 Gb/s Infiniband or 100 Gb/s Omni-Path)
a 1 or 10 Gigabit Ethernet network for services
For Ethernet connectivity, two central switches IBM G8264 connect most Ethernet nodes with 10 Gb/s or 1Gb/s. The two switches are linked with two 40Gb/s ports.
The Infiniband network is realized with three 40-port 200 Gb/s Infiniband switches.
The Omni-Path network is realized with two 48-port Omni-Path switches with a 3:1 blocking.